📜 C. Szegedy et al., "Going Deeper with Convolutions", in CVPR, 2014
논문 3줄 요약
- 모바일과 임베디드 상에서 잘 작동하기 위해 컴퓨팅 자원을 효율적으로 활용해야 한다는 요구가 높아졌다.
- 차원 축소를 통한 계산양 감소와 비선형성 추가 두 가지를 목적으로 인셉션 모듈을 도입했다.
- 인셉션 모듈을 통해 컴퓨팅 비용은 적게 상승하지만, 더 깊고 넓으면서 성능도 좋은 GoogLeNet을 구축했다.
Abstract
본 논문에서는 ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 2014에서 분류와 탐지 문제에서 좋은 성과를 거둔 '인셉션(Inception)'이라는 이름의 deep convolution neural network architecture를 제안합니다. 인셉션의 대표적인 특징은 신경망(neural network) 내부의 컴퓨팅 자원(computational resource)을 효율적으로 활용한다는 점입니다. 본 논문은 신중한 설계를 통해 컴퓨터의 연산 비용을 일정하게 유지하면서 신경망의 깊이와 너비를 증가시켰습니다. 아키텍처(architecture)의 성능을 최적화하기 위해 '헤비안 원칙(Hebbian principle)'과 '멀티 스케일 프로세싱(multi-scale processing)'의 직관에 기반하였습니다. ILSVRC 2014에 제출한 모델은 'GoogLeNet'이라 하며 22층의 깊이를 가진 네트워크로, 분류와 탐지 문제에 대해 성능을 평가하였습니다.
1. Introduction
2012년부터 3년 동안, 딥러닝과 convolution 네트워크의 발전으로 객체 탐지(object detection)와 객체 분류(object classification) 분야의 성능이 급격히 향상하였습니다. 고무적이었던 것은 단순히 '더 강력한 하드웨어'나 '더 큰 데이터셋(dataset)', '더 큰 모델'을 사용한 결과가 아닌, '새로운 아이디어'나 '알고리즘' 그리고 '개선된 네트워크 아키텍처'를 사용한 결과였습니다.
또한, 모바일과 임베디드(embedded) 상에서 운영하기 위해서는 알고리즘의 효율성, 특히 전력과 메모리의 효율적인 사용이 중요해졌습니다. 본 논문에서는 정확도(accuracy)의 수치보다 효율성을 고려하여 심층(deep) 아키텍처를 설계하였습니다.

본 논문은 컴퓨터 비전(Computer Vision, CV)을 위한 효율적인 심층 신경망(deep neural network)의 아키텍처에 집중합니다. 본 논문의 '인셉션(Inception)'은 Network-in-network [M. Lin et al., 2013]와 영화 인셉션에서 그 이름을 따왔습니다. 논문에서 'deep'이라는 단어는 두 가지의 의미로 사용합니다. '인셉션 모듈'이라는 새로운 구조를 도입한다는 의미와 네트워크의 깊이가 깊어진다는 직접적인 의미입니다.
2. Related Work
LeNet [Y. LeCun, 1998]을 시작으로 Convolutional Neural Network (CNN)은 표준 구조를 갖게 되었습니다. 표준 구조는 누적된 Convolution layer 뒤에 하나 이상의 Fully-connected layer (FC layer)가 이어지는 형태를 말합니다. 여기에 contrast normalization과 max-pooling을 연결하기도 했습니다. ImageNet과 같은 대규모 데이터셋을 이용하는 경우, 계층(layer)의 수와 너비를 늘리면서 드롭 아웃(dropout)을 통해 과적합(overfitting) 문제를 해결하는 것이 추세였습니다.

Max-pooling layer가 정확한 공간 정보를 상실하게 만든다는 우려에도 불구하고, AlexNet [A. krizhevsk et al., 2012]은 위치 식별(localization)과 객체 탐지, 사람의 자세를 추정(human pose estimation)하는 문제에서 좋은 결과를 만들었습니다.
영장류 시각 피질(primate visual cortex)에 대한 신경 과학 모델에서 영감을 얻은 Serre 연구진은 다양한 규모의 이미지를 다루기 위해 서로 다른 크기의 고정된 Gabor 필터를 사용하였습니다. 본 논문에서도 이와 비슷한 전략을 사용합니다. 하지만 인셉션 아키텍처의 모든 필터가 학습되었다는 점이 다릅니다. 또한, GoogLeNet 모델의 경우 인셉션 계층을 여러 번 반복하여 22층의 심층 모델을 만듭니다.
Lin 연구진에서 제시한 Network-in-network (NIN)는 신경망의 표현력(representational power of neural networks)을 높이기 위한 접근 방식입니다. 그들은 $ 1\times1 $ convolution layer를 네트워크에 추가하여 모델의 깊이를 증가시켰습니다. 본 논문에서는 $ 1\times1 $ convolution layer를 2가지 목적으로 사용합니다. 가장 중요한 목적은 컴퓨팅 병목 현상(bottleneck)을 제거하기 위하여 차원을 축소하는 모듈로 이용하는 것입니다. 이 접근 방식을 통해 네트워크의 크기가 제한되는 것을 막았습니다. 두 번째 목적은 큰 성능의 저하 없이 네트워크의 깊이와 너비를 증가시키는 것이었습니다.
2014년 객체 탐지 문제의 state-of-the-art (SOTA) 연구는 Girshick 연구진의 Regions with Convolutional Neural Network (R-CNN) [R. B. Girshick et al., 2014]이었습니다. R-CNN은 탐지 문제를 크게 두 단계로 분해했습니다.
- 색상(color)과 질감(texture) 같은 낮은 수준의 특징(low-level feature)을 활용하여 카테고리에 제한되지 않는 방식(category-agnostic fashion)으로 객체의 위치에 대한 제안(location proposal)을 생성합니다.
- CNN 분류기를 활용하여 제안한 위치의 객체에 대하여 카테고리를 분류합니다.
본 논문에서는 객체 탐지 문제에서 해당 연구와 유사한 파이프 라인을 적용했습니다. 하지만 경계 상자(bounding box)의 높은 재현율(recall)을 위한 Multi-box 예측 방법과 경계 상자의 제안을 보다 잘 분류하기 위한 앙상블 방법, 이 두 단계를 개선하는 방법에서 차이가 있습니다.

3. Motivation and High Level Considerations
심승 신경망의 성능을 개선하는 가장 간단한 방법은 그 크기를 증가시키는 것입니다. 이는 깊이(네트워크의 계층 수)와 너비(각 계층의 유닛 수)를 모두 늘리는 것을 의미합니다. 하지만, 이 간단한 해결책에는 아래의 두 가지 문제가 존재합니다.

- 모델의 크기가 크다는 것은 많은 매개변수(parameter)를 가진다는 것을 의미합니다. 이는 네트워크가 더 쉽게 과적합하도록 만듭니다. 이러한 현상은 특히 라벨링된 학습 데이터셋의 양이 적을 때 더 잘 나타납니다. 이는 잘 라벨링된 데이터셋을 구하기 어렵고 비용이 많이 들기 때문에 생겨난 병목 현상입니다. 또한, 전문 인력이더라도 그림 4의 ImageNet 이미지를 정확하게 분류하기는 어렵습니다.
- 네트워크의 크기가 증가함에 따라 컴퓨팅 자원이 급격하게 증가합니다. 컴퓨팅 예산은 항상 한정적입니다. 따라서 성능을 높이는 것이 주된 목적이더라도, 컴퓨팅 자원을 효율적으로 분배하는 것이 네트워크의 크기를 무분별하게 키우는 것보다 바람직합니다.
위 두 가지 문제를 해결하기 위한 근본적인 방법은 FC layer나 convolution layer 내부를 희소 층(spares layer)으로 교체하여 희소성(sparsity)을 부여하는 것입니다. 이 방법은 생물학적 시스템을 모방했다는 것 외에도 Arora 연구진의 연구로부터 견고한 이론적 토대를 얻을 수 있다는 장점이 있습니다. Arora 연구진의 주요 결과는 다음과 같습니다. 데이터셋의 확률 분포를 희소하고 큰 심층 신경망으로 나타낼 수 있다면, 앞선 계층의 활성화 값들의 상관 관계를 분석하고 상관 관계가 높은 결과를 가진 뉴런들을 군집화(clustering)함으로써 최적화된 네트워크를 구성할 수 있습니다. 이는 수학적 증명으로 매우 엄격한 조건들이 요구됩니다. 하지만 헤비안 법칙의 '동시에 활성화된 뉴런은 서로 연관이 있다'는 사실을 떠올려 보면, 실제로는 덜 엄격한 조건에서도 적용 가능하다는 것을 알 수 있습니다.
안타깝게도 오늘날의 컴퓨팅 인프라는 불균일하고 희소한 데이터 구조를 다룰 때 매우 비효율적입니다. 심지어 희소성을 도입하여 계산 수를 100배 감소하더라도, 조회와 캐시 누락(cache miss)의 계산 비용이 압도적이기 때문에 희소 행렬(sparse matrix)로 전환하는 효과는 거의 나타나지 않습니다. 또한, 균일하지 않은 희소 모델은 더 복잡한 엔지니어링과 컴퓨팅 인프라를 요구합니다. 초기에는 대칭성을 깨고 학습을 향상하기 위해 특징 차원에서 랜덤하거나 sparse connection 테이블을 사용하는 것이 추세였습니다. 하지만 병렬 연산에 더 최적화하기 위해 AlexNet처럼 full connection을 이용하는 방식으로 다시 바뀌었습니다. 2014년 CV 분야의 SOTA 아키텍처들은 컴퓨팅 인프라의 한계를 극복하기 위해 균일한 구조를 갖고 있습니다. 많은 수의 필터와 큰 배치 사이즈에서도 효율적인 조밀 연산(dense computation)이 가능하도록 고안했습니다.
이는 조밀 행렬이 연산에 적합한 하드웨어를 활용한다는 조건에서, 앞서 이론에서 제시한 것처럼 필터 수준과 같은 중간 단계에서 희소성을 이용할 방법이 있는지에 대한 의문으로 이어집니다. 희소 행렬의 연산(sparse matrix computation)과 관련된 연구들은 희소 행렬을 군집화하여 상대적으로 조밀한 하위 행렬(dense submatrix)을 만드는 방법이 희소 행렬곱(sparse matrix multiplication)에서 더 괜찮은 성능을 보인다고 언급합니다. 이러한 방법은 가까운 미래에 불균일한 딥러닝 아키텍처를 자동으로 구축하는 기법으로 유사하게 활용될 수 있습니다.
인셉션은 희소 구조(sparse structure)에 대한 근사화를 포함하여 조밀하면서도 쉽게 사용할 수 있도록 정교하게 설계된 네트워크 위상 구축(network topology construction) 알고리즘을 평가하는 사례 연구에서 시작되었습니다. 추측에 근거했던 프로젝트임에도 불구하고 NIN에 기반한 기존의 네트워크들과 비교했을 때, 조기에 성능이 조금 더 향상된 것을 관찰했습니다. 이는 이후 약간의 튜닝으로 격차가 더 벌어지게 됩니다. 또한, 인셉션을 R-CNN과 Scalable object detection [D. Erhan et al., 2014]의 기초 네트워크로 사용할 경우, 객체 위치 식별과 객체 탐지 문제에서 특히 유용하다는 것을 확인할 수 있었습니다.
4. Architectural Details
인셉션의 핵심 아이디어는 최적의 지역적 희소 구조(optimal local sparse structure)로 근사화하고 이를 쉽게 사용 가능한 조밀한 구성 요소(dense component)로 구성할지에 대한 방법을 찾는 것입니다. 이를 위해 최적의 지역 구조(optimal local structure)를 찾고 이를 공간적으로 반복합니다. Arora 연구진은 마지막 계층의 상관 관계를 분석하고 높은 상관관계의 유닛들을 군집화하는 방식의 layer-by-layer 구조를 제안합니다. 군집들은 다음 계층의 유닛으로 구성되고 이전 계층의 유닛과 연결됩니다. 본 연구에서는 이전 계층의 각 유닛이 입력 이미지의 일부 영역에 해당하며, 이들은 필터 뱅크(filter bank)라는 그룹으로 만들어진다고 가정합니다. 하위 계층(입력과 가까운 계층)에서는 상관관계가 높은 유닛들이 로컬 영역에 집중됩니다. 이는 한 영역에 많은 군집들이 집중된다는 뜻이기에 NIN에서 제안한 것처럼 다음 계층에서 $ 1\times1 $ convolution layer로 처리할 수 있습니다. 인셉션 아키텍처는 패치 정렬(patch-alignment) 문제를 피하기 위해 필터의 크기를 $ 1\times1 $, $ 3\times3 $, $ 5\times5 $로 제한했습니다. 여기서 제안하는 아키텍처는 다음 계층의 입력값을 구성하는 출력 필터 뱅크(output filter bank)로 구성된 계층의 조합을 의미합니다. 출력 필터 뱅크는 단일 출력 벡터를 합친 것입니다. 또한, pooling 작업이 convolution 네트워크의 성공을 위해 필수적이었기에, 각 단계에 병렬 pooling 경로를 추가함으로써 좋은 영향을 더해줍니다.

인셉션 모듈을 쌓아 올리면 출력값의 상관관계는 매번 달라질 수 있습니다. 높은 계층(출력과 가까운 계층)은 높은 수준으로 추상화된 특징을 추출하므로 공간 집중도(spatial concentration)가 떨어질 것으로 예상됩니다. 따라서 $ 3\times3 $과 $ 5\times5 $ convolution layer의 비율은 높은 계층으로 갈수록 증가해야 합니다.
인셉션 모듈의 한 가지 큰 문제는 단순한 형태(naiive version)에서도 필터의 수가 많아지면 $ 5\times5 $ convolution layer를 적은 수로 쌓더라도 계산양이 매우 커진다는 것입니다. pooling 유닛을 추가하면 이 문제가 더 뚜렷하게 드러납니다. 이는 출력값의 채널 수가 이전 계층의 필터수와 같기 때문에 생긴 문제입니다. 이 아키텍처는 최적의 희소 구조를 찾을 수 있지만, 매우 비효율적으로 수행되어 몇 단계만에 컴퓨팅 자원을 터트릴 수 있습니다.
이는 인셉션의 두 번째 아이디어로 이어집니다. 컴퓨팅 요구사항이 너무 많이 증가할 경우, 반대로 차원을 축소하자는 아이디어입니다. 낮은 차원의 임베딩은 상대적으로 큰 이미지 패치에 대해 많은 정보를 포함한다는 성공적인 임베딩에 기반한 방법입니다. 하지만, 이러한 임베딩은 조밀한 정보로 형태와 정보를 압축하였기 때문에 처리하기 어려워진다는 문제가 있습니다. Arora 연구진의 조건에 따르면, 압축된 표현은 대부분의 영역에서 희소하게 유지되어야 하며 필요한 경우에만 신호를 압축해야 합니다. 즉, $ 1\times1 $ convolution이 계산양이 큰 $ 3\times3 $과 $ 5\times5 $ convolution이전에 사용되어 차원을 축소해야 합니다. 이를 통해 계산양이 감소하는 효과 외에도 ReLU (Recified Linear Unit)를 사용함으로써 비선형성을 더해주는 효과를 얻습니다. 최종 결과는 아래의 그림 6으로 묘사되었습니다.

인셉션은 그림 6처럼 모듈들을 쌓아서 구성한 네트워크이며, 간혹 그리드(grid)의 해상도(resolution)를 절반으로 줄이기 위해 스트라이드(stride)가 2인 max-pooling을 사용합니다. 학습 과정에서 메모리를 효율적으로 사용하기 위해 낮은 계층에서는 기존의 convolution 방식을 유지하고 높은 계층에서만 인셉션 모듈을 사용하는 것이 좋습니다. 이는 필수적인 것은 아니며, 비효율적인 인프라를 반영한 것 뿐입니다.
인셉션의 유용한 점은 후반부의 계층에서도 계산 복잡도가 제어 불가능하게 커지지 않으면서, 각 계층의 유닛 수를 크게 늘릴 수 있다는 것입니다. 이는 큰 크기의 패치로 인해 계산 비용이 큰 convolution layer 이전에 차원을 축소함으로써 제어합니다. 또한, 이 설계는 시각적 정보를 다양한 척도로 처리하고 종합함으로써, 다음 계층에서 서로 다른 척도로부터 특성을 동시에 추상화한다는 실무적인 직관을 따릅니다.
컴퓨팅 자원을 개선한 이 방법은 어려움 없이 계층의 깊이나 너비를 늘릴 수 있게 만듭니다. 인셉션을 활용하면 다소 성능이 떨어지지만, 계산양은 더 적으면서 깊고 넓은 네트워크를 구축할 수 있습니다.
5. GoogLeNet
'GoogLeNet'은 ILSVRC 2014 대회에 제출한 모델로, 인셉션 아키텍처를 적용하였습니다. 약간 더 좋은 성능을 가진 더 깊고 넓은 인셉션 네트워크를 사용했지만, 이를 앙상블했을 때는 약간의 성능만이 향상되었습니다. 본 논문에서는 정확한 구조적 매개변수의 영향이 상대적으로 미미하다는 경험적 증거를 바탕으로 네트워크의 세부 정보는 생략합니다. 아래의 표 1은 대회에서 사용한 일반적인 GoogLeNet의 구조를 보여줍니다. 서로 다른 이미지 패치 샘플링 방법으로 학습된 네트워크들의 7개 가운데 6개의 모델이 앙상블에 사용되었습니다.

인셉션 모듈을 포함한 모든 convolution layer는 ReLU를 활성화 함수로 사용합니다. receptive field의 크기는 $ 224\times224 $로 RGB 색 채널을 가지며 zero-mean을 적용했습니다. '#$ 3\times3 $ reduce'와 "#$ 5\times5 $ reduce'는 $ 3\times3 $과 $ 5\times5 $ convolution layer 이전에 사용된 reduction layer의 $ 1\times1 $ 필터의 개수를 의미합니다. 'pool proj' 열은 max-pooling 이후에 따라오는 projection layer의 $ 1\times1 $ 필터의 개수를 나타냅니다. 모든 reduction/projection layer에는 ReLU가 적용됩니다.
네트워크는 연산 효율성과 실용성을 염두에 두고 설계하였습니다. 메모리가 작은 경우를 포함해, 컴퓨팅 자원이 제한된 기기들에서도 추론(inference)을 수행할 수 있도록 하였습니다. 네트워크에 linear layer를 추가했음에도 분류기 이전에 'avg pool'을 사용한 것은 NIN을 따른 것입니다. linear layer는 네트워크를 다른 데이터셋에 쉽게 적응할 수 있도록 하지만, 대부분은 특정 효과를 위해 사용하기보다는 편의상 사용합니다. FC layer를 avg pool layer로 바꾸면 상위 1개의 정확도(top-1 accuracy)가 약 0.6% 향상됩니다. FC layer를 제거한 후에도 드롭아웃은 필수적으로 사용합니다.
네트워크가 상대적으로 깊어지면서 모든 계층을 통해 기울기가 효과적으로 역전파(propagate gradients back)하는 방법이 중요해졌습니다. 같은 문제에서 얕은 네트워크가 더 강력한 성능을 보이는 것은 네트워크 중간에서 생성되는 특성들이 식별성이 높아야 함을 시사하고 있습니다. 본 연구는 '보조 분류기(auxiliary classifier)'를 중간 계층에 추가함으로써, 낮은 계층에서 식별성을 부여하고자 했습니다. 이는 규제화(Regularization)의 효과와 함께 기울기 소실(vanishing gradient) 문제를 해결하기 위한 방법이었습니다. 학습 과정에서 보조 분류기의 오차에 가중치를 적용하여 네트워크에 전체 손실에 더합니다. 본 연구에서는 보조 분류기의 오차에 0.3을 곱했습니다. 추론 과정에서는 보조 분류기를 제거합니다. 대조군 실험에서 보조 분류기의 효과는 상대적으로 미미(약 0.5% 성능 향상)하며 하나의 보조 분류기만 존재하여도 동일한 효과를 얻을 수 있었습니다.
보조 분류기를 포함한 추가적인 네트워크의 정확한 구조는 아래와 같습니다.
- average pooling layer는 필터 크기가 $ 5\times5 $이고 스트라이드가 3입니다. (4a)는 $ 4\times4\times512 $를 출력하고 (4d)는 $ 4\times4\times528 $을 출력합니다.
- $ 1\times1 $ convolution layer(128 필터)를 차원 축소와 비선형성을 추가하기 위해 사용했습니다.
- FC layer는 1024개의 유닛을 가졌으며 ReLU를 활성화 함수로 사용합니다.
- 드롭아웃을 0.7 적용합니다.
- linear layer에 소포트맥스(softmax)를 사용합니다(주 분류기와 동일한 1000개의 클래스를 예측. 추론 시에는 제거함).
최종적으로 구축한 네트워크는 아래의 그림 7로 정리하였습니다.

6. Training Methodology
GoogLeNet은 DistBelief [J. Dean et al., 2012]라는 분산 기계 학습 시스템을 활용하여 적절한 양의 모델과 데이터 병렬성(data-parallelism)을 사용하여 학습하였습니다. 옵티마이저로는 asynchronous Stochastic Gradient Descent (SGD) with 0.9 momentum을 사용하였고, 8 에폭마다 4%씩 학습률을 낮추도록 학습 스케줄을 조정했습니다.
이미지 샘플링 방법은 대회를 진행하면서 크게 바뀌었습니다. 이미 수렴된 모델들의 경우, 드롭아웃과 학습률 같은 하이퍼 파라미터(hyperparameter)를 바꾸는 것을 통해 학습했습니다. 따라서 네트워크를 학습하는 가장 효율적인 하나의 방법을 안내하는 것은 어렵습니다. 설상가상으로 Howard의 연구[A. G. Howard, 2013]에 영감을 받아 일부 모델들은 상대적으로 작은 크기의 crop으로 주로 학습하였지만, 몇몇은 더 큰 crop으로 학습하였습니다. 대회 이후, 가로와 세로 비율을 [$ \frac{3}{4}, \frac{4}{3}]로 제한하여 8%에서 100%의 크기까지 균등한 분포로 패치 샘플링하는 것의 효과가 우수하다는 것을 확인하였습니다. 또한 Howard의 연구에서 광도 왜곡(photometric distortion)이 과적합을 방지하는데 유용하다는 것을 발견했습니다.
7. ILSVRC 2014 Classification Challenge Setup and Results
ILSVRC 2014 분류 문제는 이미지를 ImageNet의 1000개의 카테고리 가운데 하나로 분류하는 작업을 포함합니다. 120만 장의 이미지가 학습 과정에서 사용되었으며, 검증과 테스트 과정에는 각각 5만 장과 10만 장을 사용하였습니다. 각 이미지는 하나의 참 카테고리와 연관되었으며, 분류기의 예측 중 높은 점수를 기반으로 성능을 측정합니다. ILSVRC 대회에서는 상위 5개의 오차율을 기준으로 순위를 매겼습니다.
상위 1개의 정확률(top-1 accuracy rate)
처음 예측한 부류(class)와 실제 참값(ground truth)을 비교하여 측정
상위 5개의 오차율(top-5 error rate)
예측한 상위 5개의 부류와 실제 참값을 비교하여 측정. 순위와 관계없이 상위 5개의 부류 내에 참값이 포함될 경우 올바르게 분류한 것으로 간주함
GoogLeNet은 외부 데이터를 학습하지 않고 대회에 참가했습니다. 본 논문에서 언급한 학습 방법 외에도 테스트 과정에서 더 좋은 성능을 얻기 위해 여러가지 기법을 적용하였습니다. 이는 아래에 설명하겠습니다.
- 동일한 GoogLeNet 모델의 7가지 버전(더 넓은 버전을 하나 포함)을 독립적으로 학습하고, 이들을 이용하여 앙상블 예측하였습니다. 모델들은 동일한 초기값과 학습률 정책을 사용하여 학습했습니다. 학습 데이터를 무작위로 입력하기 때문에 이미지 순서와 샘플링 방법에만 차이가 있습니다.
- 테스트하는 동안, AlexNet보다 적극적인 crop 방법을 도입하였습니다. 특히 이미지의 크기가 짧은 면을 기준으로 4가지(256, 288, 320, 352)의 크기로 조절하였습니다. 크기가 조정된 이미지에서 좌측, 중앙, 우측을 상자로 취했습니다(세로 이미지의 경우 위, 중간, 아래로 상자를 취함). 각 사각형에 대해 4개의 모서리와 중앙을 기준으로 $ 224\times224 $의 사이즈로 crop하고 사각형 자체의 크기를 $ 224\times224 $로 조정한 것과 좌우 대칭한 버전을 취합니다. 이를 통해 이미지 별로 $ 4\times3\times6\times2=144 $의 잘린 이미지가 생성됩니다. Howard의 연구와 비슷한 접근 방법을 사용하였지만, 본 논문에서 제안한 방법이 더 좋다는 것을 경험적으로 검증하였습니다. 충분한 개수의 crop이 존재하면 더 많은 crop을 추가하는 것의 이점이 미미해지므로, 실제로는 이처럼 공격적인 crop이 필요하지 않을 수 있습니다.
- 최종 예측 결과를 얻기 위해 여러 crop과 모든 개별 분류기에 대한 소프트맥스 확률을 평균 내어 구합니다. 실험에서는 crop에 대한 max-pooling과 분류기에 대한 평균을 통해 검증 데이터에 대한 대안책을 분석하였지만, 단순한 평균보다 낮은 성능을 얻었습니다.
본 논문의 나머지 부분에서는 최종 제출한 모델의 전반적인 성능에 기여한 여러 요소를 분석합니다.
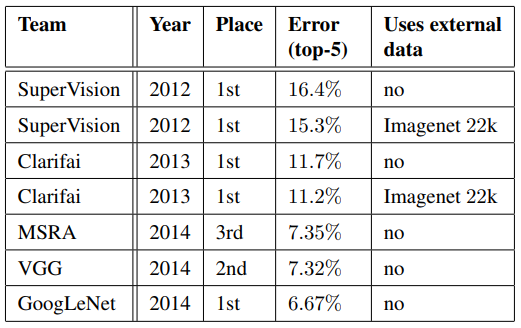
대회에 최종 제출한 결과, 검증과 테스트 데이터 모두 상위 5개의 오차율에서 6.67%를 기록해 1위를 차지하였습니다. 이는 2012년의 SuperVision에 비하여 56.5%가 상대적으로 감소한 수치이며, 2013년 최고 성능의 접근법이었던 Clarifai에 비하여 약 40%가 감소한 수치입니다. 표 2는 2012년부터 2014년까지 3년간 상위 순위를 거둔 접근법의 결과를 보여주고 있습니다.

위의 표 3은 예측 과정에서 모델과 crop의 수를 변경하는 테스트를 통하여 얻은 결과를 분석했습니다. 하나의 모델을 사용할 경우에는 검증 데이터에서 상위 1개의 오차율이 가장 낮은 모델을 선택했습니다. 테스트 데이터에 과적합되지 않도록 검증 데이터에 대한 결과만을 참고합니다.
8. ILSVRC 2014 Detection Challenge Setup and Results
ILSVRC 탐지 문제는 200개의 부류 객체 주위에 경계 상자를 생성합니다. 탐지된 객체가 참값과 일치하고 경계 상자의 50% 이상 겹치는 경우(Jaccard index 사용) 정답으로 간주합니다. 관련 없는 탐지는 거짓 긍정(false positive)으로 간주하여 패널티를 부여합니다. 분류 문제와 달리, 각 이미지에는 많은 객체가 포함되거나 없는 경우도 있으며 객체의 크기가 다를 수 있습니다. 성능은 mean Average Precision (mAP)를 사용하여 측정합니다. GoogLeNet은 R-CNN과 유사한 접근 방법을 취하지만, 영역 분류기에 인셉션 모델을 추가하였습니다. 또한, 선택적 탐색(selective search [K. E. A. van de Sande et al., 2011])을 경계 상자의 재현율을 높이기 위해 multi-box 예측과 결합하여 객체의 위치를 제안하는 단계(region proposal step)를 강화했습니다. 거짓 긍정 수를 줄이기 위해, super-pixel의 사이즈를 2배로 증가시켰습니다. 여기에 mult-box로부터 나온 200개의 객체의 위치에 대한 제안을 추가하였습니다. 총 개수는 R-CNN의 객체의 위치에 대한 제안의 약 60% 정도지만, 적용 범위(coverage)는 92%에서 93%로 늘어났습니다. 객체의 위치에 대한 제안 개수는 줄어들고 적용 범위는 늘어남으로써 단일 모델의 mAP가 1% 향상하는 효과를 얻었습니다. 마지막으로 제안된 객체의 분류에는 6개의 GoogLeNet을 앙상블하였고, 이를 통해 정확도를 40%에서 43.9%로 높였습니다.

표 4는 탐지 문제에서 상위 순위의 접근법과 초기 버전 이후의 변화를 보여주고 있습니다. 2013년의 결과와 비교하면 정확도가 거의 2배 가까이 높아졌습니다. 또한, 2014년 최고 성과를 얻은 팀들 모두 CNN을 사용했음을 확인할 수 있습니다. 표 4는 각 팀의 공통된 전략을 보여줍니다. 전략은 외부 데이터 사용 여부, 앙상블 모델인지 맥락적 모델(contextual model)인지를 말합니다. 표 4에서 외부 데이터는 일반적으로 ILSVRC 2012 분류 데이터를 의미합니다. 일부 팀에서는 객체 위치 데이터(localization dat)의 사용을 언급했습니다. 객체 위치 식별 경계 상자(localization bounding box)는 탐지 데이터에 포함되지 않았으므로, 분류 문제와 같은 방식으로 경계 상자의 regressor를 사전 학습할 수 있습니다. GoogLeNet은 객체 위치 데이터를 사전학습에 이용하지 않았습니다.
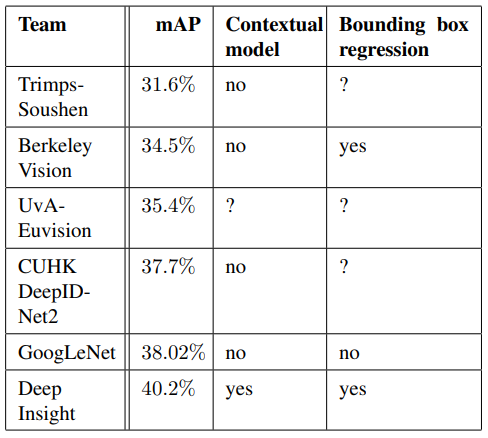
표 5는 단일 모델만을 사용한 결과를 비교합니다. 최고 성능인 Deep Insight은 3개의 모델을 앙상블하여 0.3점이 향상된 반면, GoogLeNet은 앙상블을 통해 훨씬 강력한 성능을 얻을 수 있습니다.
9. Conclusions
본 논문의 실험 결과는 쉽게 이용 가능한 dense building block을 통하여 최적의 희소 구조로 근사화하는 것이 CV의 신경망 성능을 개선하는 효과적인 방법이라는 확실한 증거를 제시합니다. 이 방법의 가장 큰 장점은 얕고 좁은 아키텍처에 비하여 컴퓨팅 비용이 조금 상승해도 성능은 매우 향상한다는 것입니다.
객체 탐지 문제에서는 맥락 모델과 경계 상자의 regressor를 이용하지 않았음에도 경쟁력 있는 성능을 보였습니다. 이는 인셉션 아키텍처의 강점에 대한 또 다른 증거입니다.
분류와 탐지 문제에서 인셉션을 사용하지 않은 비슷한 크기의 네트워크에 비해 적은 컴퓨팅 비용으로 비슷한 성능을 기대할 수 있습니다. 본 논문의 접근법은 보다 희소한 아키텍처로 전환하는 것이 실현 가능하며 유용한 아이디어라는 확실한 증거를 제시합니다. 이는 인셉션의 아이디어를 다른 도메인에 적용하는 것과 더불어 Arora 연구진의 연구에 기반하여 보다 희소하고 정제된 구조를 자동으로 만드는 방법을 향후 연구 과제로 제안합니다.
References
- M. Lin, Q. Chen, S. Yan, "Network in network", arXiv, 2013
- Y. LeCun, B. Boser, J. S. Denker et al., "Backpropagation applied to handwritten zip code recognition", in Neural Comput., 1998
- A. krizhevsk, I. Sutskever, and G. Hinton, "Imagenet classification with deep convolutional neural networks", in Advances in Neural Information Processing Systems, 2012
- R. B. Girshick et al., "Rich feature hierarchies for accurate object detection and semantic segmentaion", in CVPR, 2014
- D. Erhan et al., "Scalable object detection using deep neural networks", in CVPR, 2014
- J. Dean et al., "Large scale distributed deep networks", in NIPS, 2012
- A. G. Howard, "Some improvements on deep convolutional neural network based image classification", in CoPR, 2013
- K. E. A. van de Sande et al., "Segmentation as selective search for object recognition", in ICCV, 2011
* 인용된 논문은 더 있지만, 본 요약에서 언급한 논문만을 정리했습니다.
* 번역 오류는 댓글로 남겨주시면 수정하겠습니다.
'인공지능 논문 요약 > Deep Network' 카테고리의 다른 글
| Very Deep Convolutional Networks for Large-Scale Image Recognition 요약 (0) | 2021.09.21 |
|---|