💡 'Deep Learning from Scratch'와 'CS231N'을 참고하여 작성
(각 절의 넘버링은 지난 게시물에서 이어집니다)
2. 옵티마이저
지난 게시물에서는 SGD의 문제점으로 지적되었던 여러 가지 가운데 스텝 방향을 개선한 옵티마이저에 대하여 알아봤습니다. 오버슈팅(overshooting)으로 안장점(saddle point)과 지역 최솟값(local minima)을 통과하며 전역 최솟값(global minimum)을 찾던 SGD+Momentum, NAG를 직접 구현해보았습니다. 이번 게시물에서는 파라미터가 갱신된 정도에 따라 스텝 사이즈를 조정하며 학습을 진행하는 AdaGrad류의 옵티마이저에 대해 알아보겠습니다.

2.5 Adaptive Gradient (AdaGrad)
AdaGrad는 모든 파라미터에서 학습 보폭이 동일하다는 SGD의 문제점을 개선하기 위해 등장했습니다. 신경망 학습에서 학습률(learning rate)는 매우 중요한 요소입니다. 학습률을 효과적으로 정하기 위해 '학습률 감소(learning rate decay)'가 사용되기도 합니다.
학습률 감소
학습을 진행하면서 학습률을 점차 줄이는 방법. 처음에는 큰 보폭으로 학습하였다가 조금씩 작게 학습함으로써 효과적인 학습을 유도함.
학습률을 조절하는 가장 쉬운 방법은 매개변수 '전체'의 학습률을 일괄적으로 낮추는 것입니다. 이 개념을 발전시킨 것이 바로 AdaGrad입니다. AdaGrad는 '각각의' 매개변수에 적합한 학습률을 설정합니다. 즉, AdaGrad는 개별 매개변수에 대해 적응적(adaptive)으로 학습률을 조정하며 학습합니다. AdaGrad의 수식은 아래와 같습니다.
$$ \theta_{t+1}=\theta_{t} - \frac{\eta}{\sqrt{G_{t}+\epsilon}} \odot \triangledown J(\theta_{t}) $$
$$ G_{t}=G_{t-1}+(\triangledown J(\theta_t))^2 $$
- $ G_t $ : 손실 함수 기울기의 제곱합
- $ \odot $ : 행렬의 원소별 곱셈
이를 구현하면 다음과 같습니다.
class AdaGrad:
def __init__(self, lr: float=0.01):
self.lr = lr
self.h = None
def update(self, params: Dict[str, float],
grads: Dict[str, float]) -> None:
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= \
self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)파라미터를 갱신하는 부분에서 매우 작은 값인 1e-7을 더한 것을 확인할 수 있습니다. 이는 h[key] 안에 0이 담겨 있더라도 0으로 나누는 것을 막아줍니다. 이를 시각화한 결과는 아래의 그림 2입니다.

전역 최솟값을 향해 효율적으로 움직이는 것을 그림에서 확인할 수 있습니다. 또한, 기울기에 비례하여 움직임도 점점 작아지는 것을 확인할 수 있습니다. 이는 AdaGrad의 장점이자 단점입니다. AdaGrad는 과거의 기울기를 제곱하여 계속 더해가는 성질 때문에 학습을 진행할수록 그 움직임이 약해집니다. AdaGrad를 이용하여 무한히 학습하면, 어느 순간에는 갱신량이 0이 되어 전혀 갱신하지 않는 현상이 발생합니다.
2.6 RMSProp
RMSProp은 AdaGrad를 개선한 기법입니다. RMSProp은 과거의 모든 기울기를 균일하게 더하는 것이 아닌, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영하는 형태입니다. 이를 지수이동평균(Exponential Moving Average)라고 합니다. 지수이동평균을 통해 손실 함수의 기울기 제곱합이 단순 누적되어 무한대로 발산하는 것을 막아줍니다. RMSProp의 공식은 아래와 같습니다.
$$ \theta_{t+1}=\theta_{t} - \frac{\eta}{\sqrt{G_{t}+\epsilon}} \odot \triangledown J(\theta_{t}) $$
$$ G_{t}=\gamma G_{t-1}+(1-\gamma)(\triangledown J(\theta_t))^2 $$
- $ \gamma $ : 감소율(decaying factor)
여기서 감소율은 일반적으로 0.9 혹은 0.99의 높은 값을 사용합니다. 이외의 개념들은 AdaGrad와 동일합니다. 이를 구현한 내용은 아래와 같습니다.
class RMSProp:
def __init__(self, lr: float=0.01, decay_rate: float=0.99):
self.lr = lr
self.dr = decay_rate
self.h = None
def update(self, params: Dict[str, float],
grads: Dict[str, float]) -> None:
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.dr
self.h[key] += (1- self.dr) * grads[key] * grads[key]
params[key] -= \
self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)2.7 Adaptive moment estimation (Adam)
모멘텀과 RMSProp의 방식을 합친 기법이 바로 Adam입니다. Adam은 불편 추정치(unbiased estimate)를 통해 초기에 $ m_t $에서 이동하지 못하는 것과 $ v_t $에서 너무 큰 학습 보폭을 밟는 것을 방지합니다. 이를 적용한 Adam의 수식은 다음과 같습니다.
$$ m_t = \beta_1 m_{t-1}+(1-\beta_1)\triangledown J(\theta_{t}) $$
$$ v_t = \beta_2 v_{t-1}+(1-\beta_2)(\triangledown J(\theta_{t}))^2 $$
$$ \theta_{t+1}=\theta_t - \frac{\eta}{\sqrt{\hat{v}_t+\epsilon}}\hat{m}_t $$
$$ (\hat{m}_t=\frac{m_t}{1-\beta^t_1},\ \ \hat{v}_t=\frac{m_t}{1-\beta^t_2}) $$
- $ m_t $ : 모멘텀 기법
- $ v_t $ : RMSProp 기법
- $ \beta $ : 감쇠 상수(decay constant)
- $ \hat{m_t}, \hat{v_t} $ : 불편 추정치 적용
일반적으로 $ \beta_1 $은 0.9를, $ \beta_2 $는 0.999를 사용합니다. 이를 구현한 내용은 아래와 같습니다.
class Adam:
def __init__(self, lr: float=0.001, beta1: float=0.9,
beta2: float=0.999):
self.lr = lr
self.b1 = beta1
self.b2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params: Dict[str, float],
grads: Dict[str, float]) -> None:
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
for key in params.keys():
# Momentum
self.m[key] = \
self.b1 * self.m[key] + (1 - self.b1) * grads[key]
m_hat = \
self.m[key] / (1 - self.b1 ** self.iter) # bias correcton
# RMSProp
self.v[key] = \
self.b2 * self.v[key] + (1 - self.b2) * (grads[key] ** 2)
v_hat = \
self.v[key] / (1 - self.b2 ** self.iter) # bias correcton
# Update
params[key] -= self.lr * m_hat / (np.sqrt(v_hat) + 1e-7)Adam을 시각화한 결과는 아래의 그림 3과 같습니다.

Adam의 최적화 갱신 경로를 살펴 보면, 기존의 모멘텀과 같이 오버슈팅을 하면서도 전역 최솟값을 향해 효율적으로 움직이는 것을 확인할 수 있습니다. 즉, 이는 앞서 언급한 모멘텀의 특징과 RMSProp의 특징 모두를 적용했다는 것을 말합니다.
2.8 Nesterov-accelerated Adaptive Moment Estimation (Nadam)
Nadam은 Adam에서 적용한 모멘텀 기법을 NAG로 변경하였습니다. Nadam은 Adam과 NAG의 장점을 합쳤기 때문에, Adam보다 더 빠르고 정확하게 전역 최솟값을 찾을 수 있다는 장점이 있습니다. Nadam을 구현하기 위해서는 기존의 NAG의 공식을 조금 수정할 필요가 있습니다. NAG에서 모멘텀을 조정하는 수식은 아래와 같았습니다.
$$ g_t =\triangledown J(\theta_t - \gamma m_{t-1}) $$
$$ m_t = \gamma m_{t-1} + \eta g_t $$
$$ \theta_{t+1} = \theta - m_t $$
NAG는 현재의 위치($ \theta_t $)에서 현재의 모멘텀($ \ m_t $)만큼 이동한 자리에서 기울기를 구하였습니다. 그리고 이를 이전 단계의 모멘텀에 더해줌으로써 현재의 모멘텀($ \ m_t $)를 갱신할 수 있었습니다.
위의 NAG 공식에서 파라미터 갱신을 위하여 이전 단계의 모멘텀($ m_{t-1} $)을 2번 사용했다는 것을 알 수 있습니다. Nadam은 이를 조금 변형합니다. 이전 단계의 모멘텀($ m_{t-1} $)을 대신하여 현재의 모멘텀($ m_t $)을 사용함으로써 미래의 모멘텀을 사용하는 효과를 얻었습니다. 이를 NAG의 파라미터 조정에 반영하면 다음과 같습니다.
$$ g_t=\triangledown J(\theta) $$
$$ \theta_{t+1} = \theta - (\gamma m_t + \eta g_t) $$
위의 효과를 Adam에 적용하겠습니다. 이를 위해서는 기존의 Adam이 파라미터를 수정하는 부분을 조금 더 풀어서 작성할 필요가 있습니다.
$$ \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat{v_t}+\epsilon}}\hat{m_t} $$
$$ \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat{v_t}+\epsilon}}\left(\frac{\beta_1m_{t-1}}{1-\beta_{1}^{t}}+\frac{(1-\beta_1)g_t}{1-\beta_{1}^{t}}\right) $$
$$ \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat{v_t}+\epsilon}}\left(\beta_1 \hat{m_{t-1}}+\frac{(1-\beta_1)g_t}{1-\beta_{1}^{t}}\right) $$
위에서 언급한 미래의 모멘텀을 사용하는 효과를 Adam에 적용하면, 아래와 같이 공식을 수정할 수 있습니다.
$$ \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat{v_t}+\epsilon}}\left(\beta_1 \hat{m_{t}}+\frac{(1-\beta_1)g_t}{1-\beta_{1}^{t}}\right) $$
위의 공식을 적용하여 Nadam을 구현한 내용은 아래와 같습니다.
class Nadam:
def __init__(self, lr: float=0.001, beta1: float=0.9,
beta2: float=0.999):
self.lr = lr
self.b1 = beta1
self.b2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params: Dict[str, float],
grads: Dict[str, float]) -> None:
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
for key in params.keys():
# Momentum
self.m[key] = \
self.b1 * self.m[key] + (1 - self.b1) * grads[key]
m_hat = \
self.m[key] / (1 - self.b1 ** self.iter) # bias correcton
# RMSProp
self.v[key] = \
self.b2 * self.v[key] + (1 - self.b2) * (grads[key] ** 2)
v_hat = \
self.v[key] / (1 - self.b2 ** self.iter) # bias correcton
# Update
params[key] -= \
self.lr / (np.sqrt(v_hat) + 1e-7) * \
(self.b1 * m_hat + (1 - self.b1) * \
grads[key] / (1 - (self.b1 ** self.iter)))Nadam의 시각화 결과는 다음과 같습니다.
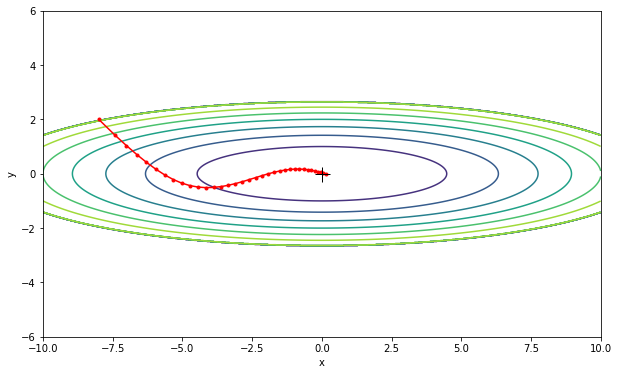
Adam과 Nadam의 시각화 결과를 비교해보면, Nadam이 더 빠르고 정확하게 전역 최솟값을 찾아낸다는 것을 확인할 수 있습니다.
3. 옵티마이저 비교
SGD를 포함하여 총 7개의 옵티마이저를 알아보았습니다. SGD를 제외한 6개의 옵티마이저를 시각화하겠습니다. 6개의 옵티마이저 모두 동일한 에폭의 학습을 진행하였습니다.

그림 5에서 사용한 기법에 따라 갱신 경로가 달라짐을 확인할 수 있습니다. 그림 5만 보면, AdaGrad와 RMSPorp이 가장 나아보입니다. 하지만 풀어야 할 문제가 무엇인지에 따라 어떤 옵티마이저를 사용해야할지 결정할 필요가 있습니다. 또한, 하이퍼파라미터를 어떻게 설정하느냐에 따라서도 그 결과가 달라집니다.

옵티마이저에 대한 최근 연구에서는 SGD가 Adam에 비하여 일반화(generalization)를 잘하지만, Adam의 속도가 SGD에 비해 훨씬 빠르다는 결론을 내렸습니다. 이 연구를 바탕으로 최근에는 Adam과 SGD의 장점을 결합하려는 시도가 있었습니다. 그중 대표적인 것이 바로 Adam을 SGD로 전환한 SWATS입니다. 또 이외에도 AMSBound와 AdaBound 등이 등장하며, Adam을 개선하기 위한 시도는 이어지고 있습니다. 이런 최신 옵티마이저는 추후의 게시물에서 다루도록 하겠습니다.
참고자료 출처
- 하용호, "자습해도 모르겠던 딥러닝, 머릿속에 인스톨시켜드립니다", https://www.slideshare.net/yongho/ss-79607172, 2017
- S. Ruder, "An overview of gradient descent optimization algorithms", https://ruder.io/optimizing-gradient-descent, 2016
'기초 > 인공지능' 카테고리의 다른 글
| 학습과 관련된 기술들 (0) | 2021.09.10 |
|---|---|
| 옵티마이저(Optimizer) (1/2) (1) | 2021.08.31 |
| 오차역전파(Back-Propagation) (0) | 2021.08.29 |
| 손실 함수(Loss function) (0) | 2021.08.28 |
| 활성화 함수(Activation function) (0) | 2021.08.26 |